GPT4All簡介(三)
前二篇介紹了GPT4All 的下載、安裝、大型語言模型(LLM)的下載、GPT4All的基本操作方式、以及GPT4All本機端RAG的使用方式。本文將介紹GPT4All的各項設定,尤其是和LLM有關的設定,因為會直接影響GenAI的生成內容。
對LLM相關參數的認識,不只是對實際使用效果有影響,對於理解LLM和生成式AI的運作方式和限制,也相當有幫助。本文將簡要說明GPT4All的各個設定項目,協助使用者瞭解各項設定的功能。
點選GPT4All軟體畫面左方側邊欄「設定」(Settings),就可以進入設定頁面,分成應用程式(Application)、模型(Model)、我的文件(LocalDocs)三個部分:
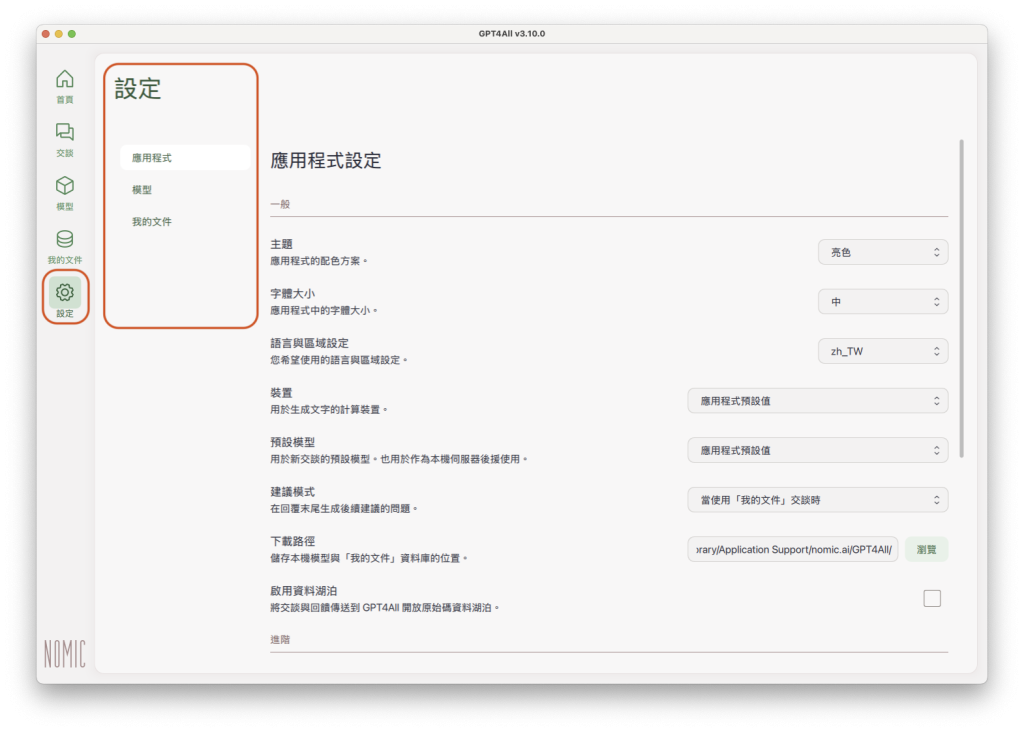
以下分別說明應用程式、模型、我的文件的各個設定項目:
應用程式設定(Application Settings)
一般設定(General)
在應用程式的「一般」設定中,除了主題顏色(Theme)、字體大小(Font Size)、介面語言(Language and Locale)(支援繁體中文zh_TW)等一般設定項目外,也包含裝置(Device)、預設模型(Default Model)、建議模式(Suggestion Mode)、下載路徑(Download Path)等設定項目:
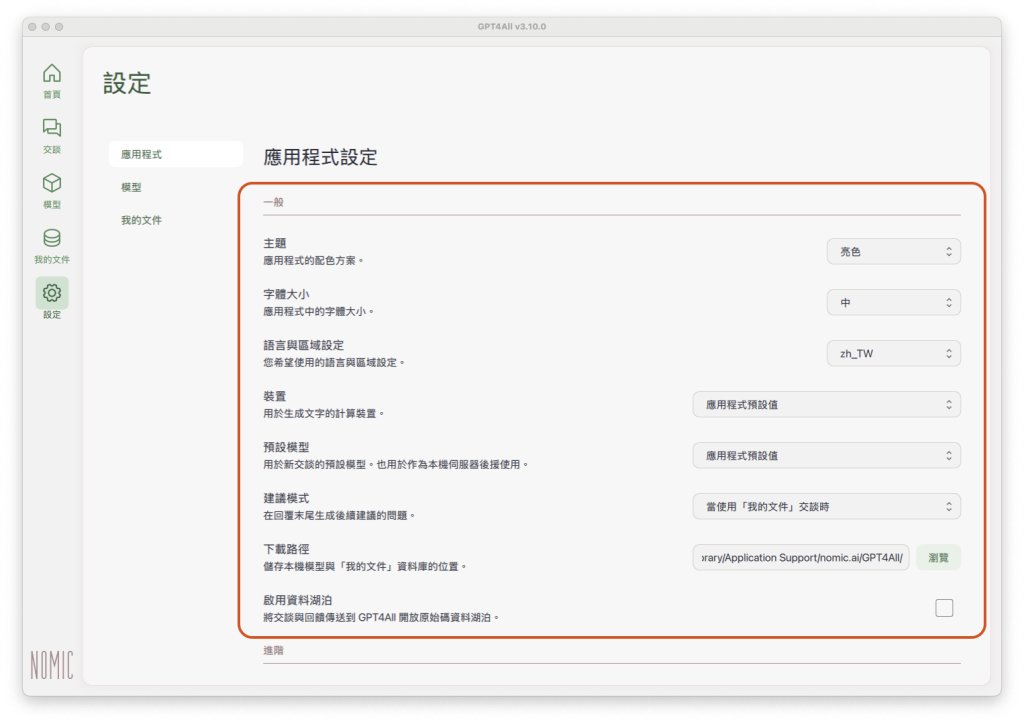
裝置:GPT4All會依照本機電腦的硬體規格(Intel/ARM、GPU、CPU…),自動設定最適合執行的裝置模式,一般情況下應該不需要修改。
預設模型:如果下載過二個以上的語言模型,可以點選這個欄目右方的下拉式選單,從已下載的語言模型清單中選擇一個模型作為預設使用的語言模型:
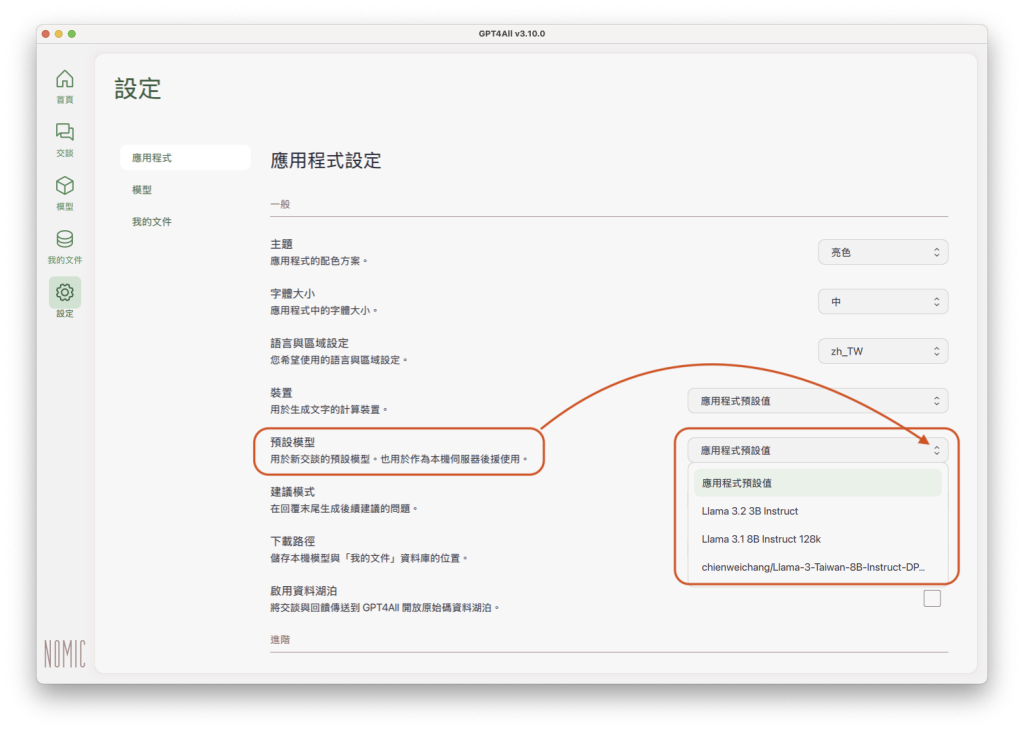
完成設定後,每次開啟新的交談時,就會預設使用設定的模型(但每次交談時,還是要按一下正中央綠色的「載入(語言模型名稱)」按鈕)。
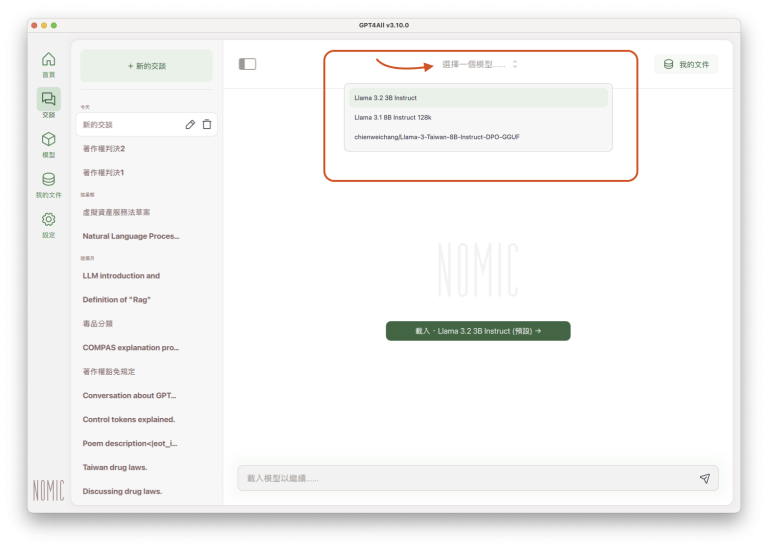
不過,即使已經設定預設使用的語言模型,每次開啟新的交談時,還是可以點選畫面中央上方的「選擇一個模型……」,從清單中選擇不同的語言模型,作為本次交談所要使用的語言模型:
建議模式:這裡可以設定是否要讓GPT4All在每次回覆內容生成之後,在回覆內容的結尾,自動產生後續提問的建議。如果選擇「當使用『我的文件』交談時」,每次使用匯入資料或文件進行交談時,GPT4All會在LLM回覆的結尾,自動產生1至3則提問建議,使用者只要點選系統建議的提問,就會自動送出提問,不必再自行輸入提問內容。其他二個選項為:「視情況允許」、或「永不」。
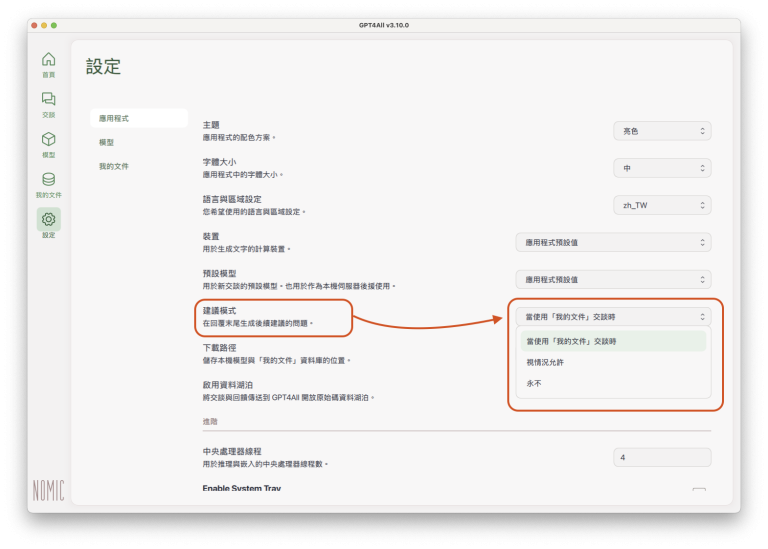
下載路徑:這是已下載的語言模型(副檔名:gguf)、「我的文件」資料庫(副檔名:db)、以及交談紀錄(副檔名:chat)的儲存位置。點選「瀏覽」按鈕,就會打開該路徑位置的資料夾,方便管理相關檔案。
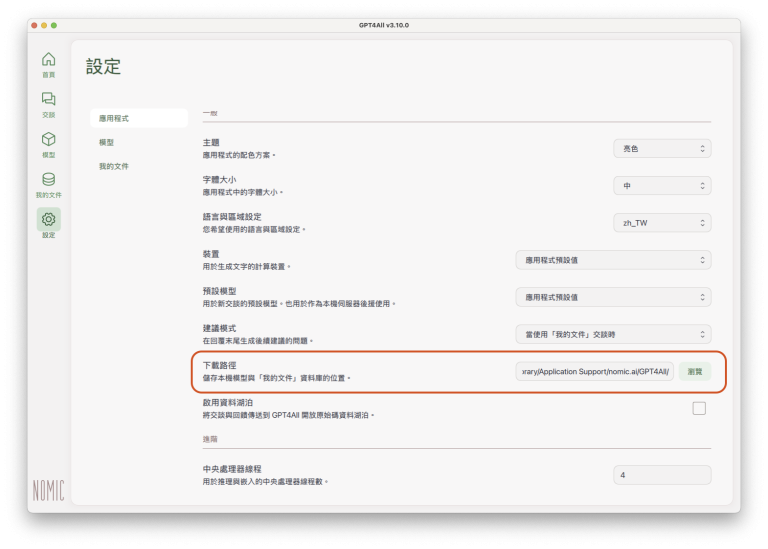
啟用資料湖泊(Enable Datalaje):這是將交談及回饋意見傳送給GPT4All、協助GPT4All產品改善的選項。如果不想回傳資料,可以保持不勾選的狀態。
進階設定(Advanced)
以下簡單說明「進階」設定的各個項目:
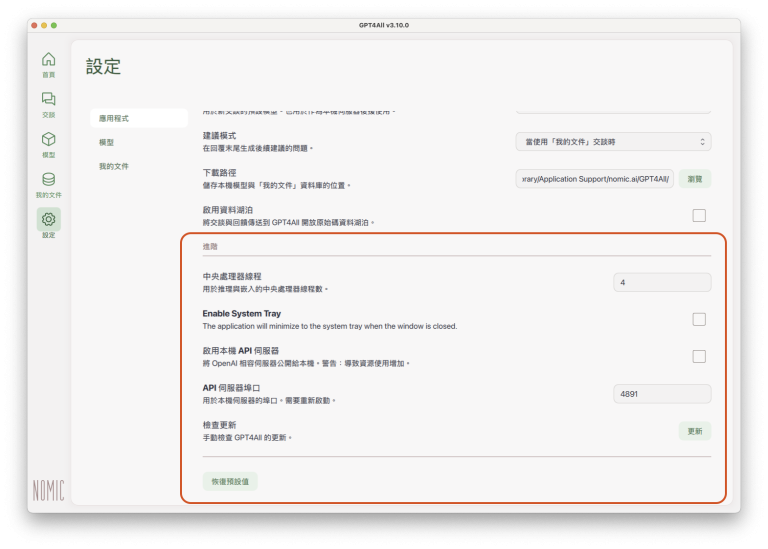
中央處理器線程(CPU Thread):這裡所謂的「線程」(thread),在台灣一般翻譯為「執行緒」。根據 Microsoft的說明,執行緒是作業系統配置處理器時間的基本單位;我們可以簡單理解為對中央處理器(CPU)運算資源的配置,由於LLM運算時需要耗費相當的電腦運算力,如果有必要,使用者可以依照本地端電腦的軟硬體規格和工作狀況,指定適當的CPU資源給GPT4All使用。使用Intel電腦的使用者,可以參考 Intel 的這篇說明,檢查自己電腦CPU的核心和執行緒的數量。
Enable System Tray:這是方便使用者執行GPT4All的快捷圖示設定,使用者如果勾選這個選項,即使關閉GPT4All,在作業系統的工作列上還是會出現GPT4All的圖示,方便使用者快速開啟GPT4All。以Windows 11為例,下圖是桌面右下角工作列上的GPT4All圖示:
啟用本機API伺服器(Enable Local API Server):如果勾選這個選項,可以在本機電腦以伺服器模式執行GPT4All,使用者可以透過HTTP連接的方式使用GPT4All,啟用伺服器模式後,就可以在localhost(127.0.0.1)存取GPT4All,URL為“http://localhost:4891/v1”,預設API Port是4891,但可以在下一個設定選項中指定其他API伺服器埠口(API Server Port)。關於伺服器模式,可以參閱GPT4All的說明文件。
API伺服器埠口(API Server Port):如果啟用前一個選項的伺服器模式,預設API Port為4891,但可以在這裡設定其他API伺服器埠口。
檢查更新(Check for Updates):點選「更新」按鈕,可以檢查是否有GPT4All更新版,若有,可以依照螢幕畫面指示,進入軟體更新程序。
恢復預設值(Restore Defaults):使用者調整過各項設定值之後,如果有必要,可以點選「恢復預設值」,將所有設定恢復為預設值。
模型設定(Model Settings)
一般設定
模型設定頁面可以調整LLM的相關參數值。頁面上半部的「名稱」(Name)和「模型檔案」(Model File),都是系統自動設定:
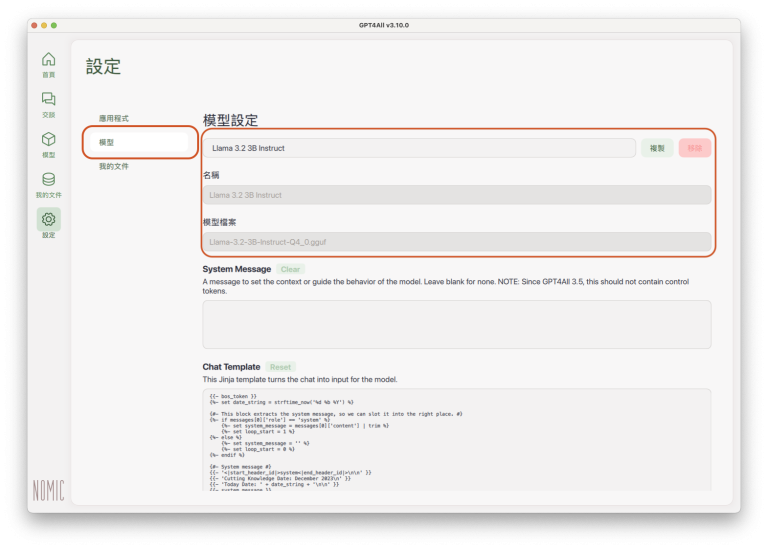
System Message:這裡可以輸入交談語境(context),也就是對LLM的一般性指示,引導LLM往指示的方向生成回覆內容。通常會由LLM模型自動設定,如果空白就表示該模型沒有預設的交談指示,但使用者也可以試著自己輸入交談指示,測試回覆內容是否有所變化;在這裡所輸入的交談指示,會適用到之後所有的交談。
Chat Template:這是該語言模型的交談模板(chat template),目的是讓LLM明白使用者(user)和LLM自己(assistant)的角色,以對話的形式完成LLM的輸入(input)與輸出(output)。通常會由LLM模型自動設定,但某些調整過的LLM(例如從Hugging Face下載、其他使用者調整過的模型),可能沒有設定交談模板,使用者可以自行設定,但使用者必須研究一下如何設定交談模板。
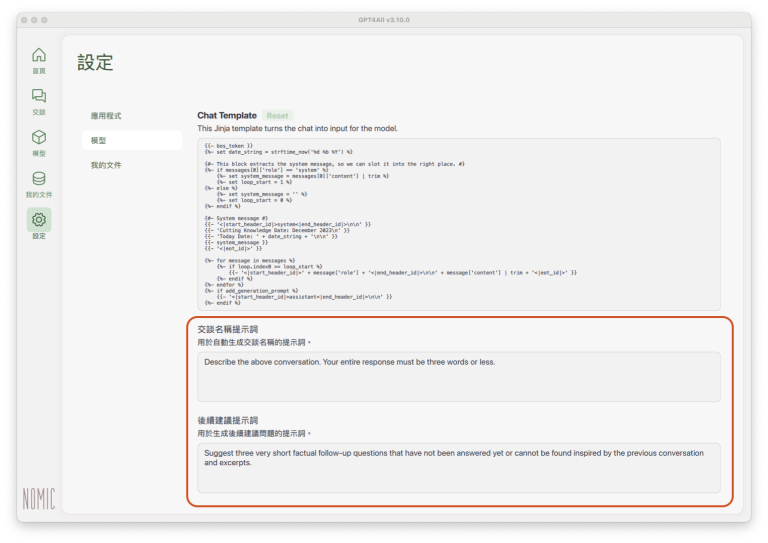
交談名稱提示詞(Chat Name Prompt):這是用來指示LLM自動為每一個交談設定名稱,讓使用者事後在瀏覽交談歷史紀錄時,比較容易根據名稱找到特定交談紀錄。
後續建議提示詞(Suggested FollowUp Prompt):這是指示LLM在每一次生成回覆之後,自動根據交談內容,產生後續提示詞的建議,方便使用者繼續針對之前的交談主題送出提示詞(prompt),並由LLM繼續生成尚未回覆過的內容。
參數調整
模型設定下半部的設定項目是LLM較常使用的參數設定,和LLM每一次交談的生成內容也有直接的關連,如果使用伺服器模式,batch size等設定值也會影響執行效能,而且這些參數也是提示工程(prompt engineering)的一部分。對不打算寫程式的人來說,GPT4All可以很方便地調整、觀察、測試LLM對相關參數的反應,對進一步理解LLM的運作方式有相當幫助。
在GPT4All「模型設定」的下半部,列出了一般較常用的參數值:
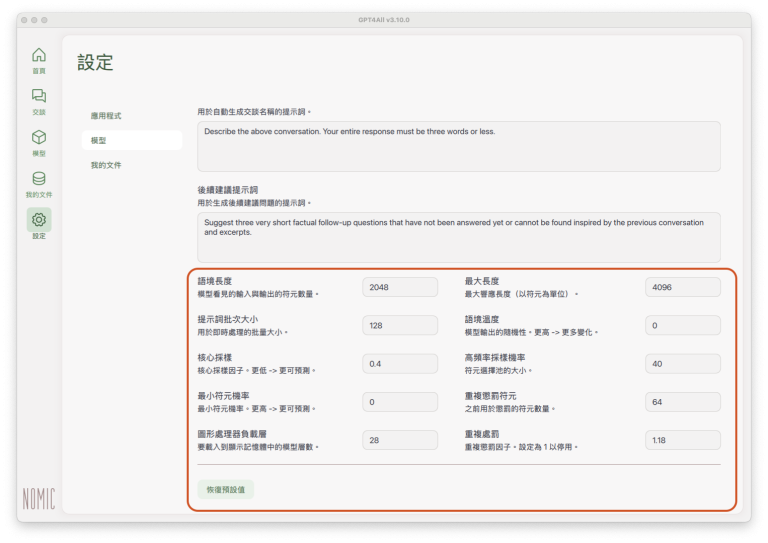
語境長度(Context Length):這裡的context length是指LLM依照提示詞(prompt)生成內容時,所能記住的提問內容(propmt)的token數量。
這裡的語境,是指前後文義(context)。在自然語言中,同樣的字詞在不同的前後文義中,很可能有不同的含義,對於以掌握自然語言為目標的LLM來說,如何正確掌握前後文義,就是重要的考慮。理論上,LLM所能處理的前後文義越長,越能正確掌握一段文字的真正意涵,回覆內容也就越貼近提示詞所要詢問的內容。
一種有趣的說法是:context length就是LLM的注意力程度(attention span)(Context Length in LLMs: What Is It and Why It Is Important,這篇文章對context length、以及各個主要LLM的context length有簡單扼要的介紹。),就像人一樣,談話對象在對話過程中的注意力程度,會直接影響談話內容的品質或有趣程度。但context length越大,所需要的電腦運算力也越大。
context length是以token為單位。token是LLM的重要概念,基本上就是指LLM對文本進行切分後的最小單位;文本必須經過整理、分段、分句、分字、甚至分字母或分部首等不同方式分切(tokenization)為token後,才能數值化為電腦可以處理的對象,目前OpenAI等收費制的GenAI服務,收費方式也是以token為計費單位。token的介紹可以參閱「一個字等於一個token嗎?」,繁體中文的tokenization,可以參閱「LLM時代下的繁體中文tokenization?」。
最大長度(Max Length):這裡的Length也是指token的長度(數量),但Max Length是指該模型的回覆(response)所能涵蓋的最大token數。
提示詞批次大小(Prompt Batch Size):這裡的批次大小(batch size),是指一個批次(batch)平行處理(parallel processing)的token數。設定或調整批次大小主要是為了提升處理速度、增進執行效能,較高的token數可以提高效率,但是對記憶體的需求也較高。這項設定應該和伺服器模式比較有關聯,例如在伺服器模式中使用batch prompting,一般單機版的使用方式應該不需要調整此項設定。
語境溫度(Temperature):設定隨機範圍 0 ~ 1。若設定為 0,隨機性最低,只選擇機率最高的 token;若設定為0.9,隨機性高,容易出現創意性的回答內容。預設值為0.7,但如果使用本機端RAG功能,在「我的文件」中匯入資料或文件、而且希望LLM回覆的內容符合貼近所匯入的資料或文件,可以試著調低temperature設定值。
核心採樣(Top-P):LLM在生成回覆內容時,是透過計算,從機率最高的token中取樣。Top-P也稱為核心採樣(nucleus sampling),是加總的機率範圍,指定LLM從這個機率分佈範圍內的token中取樣。例如:Top-P 設定為0.6,就是只考慮加總機率為前60%的token,若機率最高的四個 token A, B, C, D 機率分別為 0.25, 0.2, 0.15, 0.1,只會列入A, B, C 三個 token。Top-P如果設定為較低的值,例如0.1,LLM就只會從機率最高的10%中取樣,回覆內容就比較不會出現差異;如果設定為0.9,LLM會從機率最高的90%中取樣,回覆內容就比較容易出現差異。
設定時,Top-P和temperature可以一起列入考慮,測試不同的組合對回覆內容的影響,例如temperature=0.1, top-p=0.25,或者temperature=0.5, top-p=1等等。
高頻率採樣機率(Top-K):Top-K是指定機率最高的 token 數量;例如:若設定為 1,LLM在生成回覆時,只會選擇機率最高的一個 token。如果希望生成比較可預期、較少意外的回覆內容,可以設定較低的Top-K值。
最小符元機率(Min-P):這裡的「符元」應該是指「token」。Min-P是設定最低的機率門檻,高於Min-P的token才會列入LLM取樣範圍;如果希望比較嚴謹的回覆結果,可以設定較高的Min-P值;如果Min-P設為0,就相當於不使用此項參數。
重複懲罰符元(Repeat Penalty Tokens):這是使用「重複處罰」時(詳下述),設定所要追溯的token範圍,例如GPT4All的預設值是64,表示LLM會在使用過的64個token的範圍內決定是否有重複token以及重複頻率;越高的值,涵蓋的範圍越大,越不容易出現重複。
圖形處理器負載層(GPU Layers):這是對GPU資源的配置,若本機端電腦有GPU,可以在這裡調整設定值。
重複處罰(Repeat Penalty):以一般文本為例,某些重複出現的字詞,雖然重複出現的頻率很高,但一般而言,這些重複出現的字詞本身並沒有太大的意義,對理解文本也沒有重要影響,例如 is, the, a 等等。設定重複處罰是不希望回覆內容出現重複頻率很高、但卻和提問目標沒有太大關聯的內容。這個值如果設定為1,就表示不使用這項參數,設定為超過1的值(例如預設值為1.18),就表示不鼓勵出現重複,重複頻率越高,處罰越重。
恢復預設值(Restore Defaults):使用者調整過各項設定值之後,如果有必要,可以點選「恢復預設值」,將所有設定恢復為預設值。
我的文件設定(LocalDocs Settings)
GPT4All的特色之一,就是可以在本機端建立私有的RAG(Retrieval-Augmented Generation)系統,解決使用雲端GenAI系統時可能產生的個資、隱私、營業秘密保護的疑慮。
關於RAG,參照 LangChain 對 RAG 的說明,RAG 架構可以分成 Indexing (建立索引)和 Retrieval & Generation (擷取及生成)二個部分;關於RAG的簡要說明及基本架構流程,可以參閱前文「本機端RAG簡介」。
GPT4All「我的文件」頁面中的設定,主要就是針對RAG架構中的「indexing」(建立索引)部分:
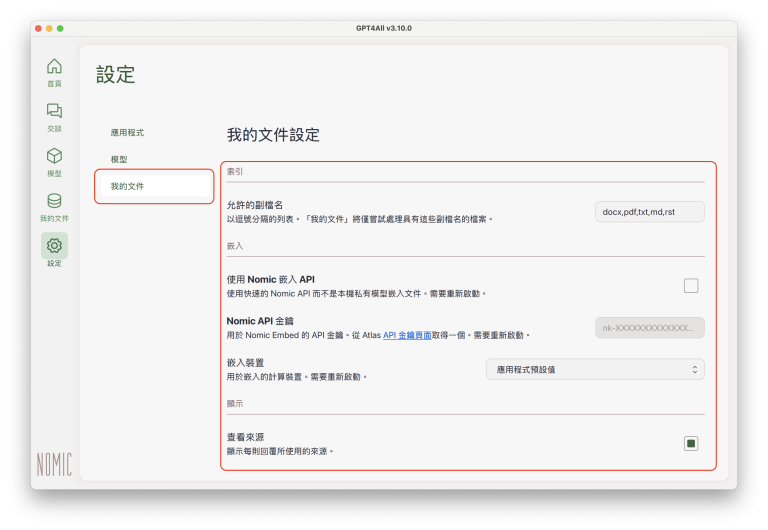
索引(Indexing)
允許的副檔名(Allowed File Extensions):這是GPT4All「我的文件」(匯入資料或文件的功能)目前所支援的檔案格式(file type),包括副檔名為docx、pdf、txt、md、以及 rst 的檔案格式。以下是這些檔案格式的簡單說明:
DOCX:Microsoft Office Word檔案。
PDF:這是網路上儲存、分享及傳輸文件最常使用的檔案格式之一;但PDF檔案可以概略地分為二種:一種是原生格式的PDF(native PDF),例如直接以文字檔(doc, docx, 或 text)轉成的PDF,這種PDF可以直接編輯或搜尋文本內容,使用上比較沒有問題;另一種是從紙本掃描成電子檔的PDF(scanned PDF),這種PDF性質上更像圖片檔,使用者可能無法直接編輯或搜尋文本內容,在使用之前,就必須先使用OCR或GenAI轉換成可以編輯或搜尋的文字檔,才能讓LLM順利解讀。
TXT:這就是一般常見、最簡單易用的文字檔。
MD:以 Markdown 語言撰寫的文本檔案,這是網路上越來越普遍、部落客、工程師及系統開發者愛用的文本格式,性質上類似HTML的標記語言(markup language),但是比HTML更簡單易學,即使不使用MD軟體也可以直接辨讀;GenAI蓬勃發展以來,MD格式的文本似乎也越來越常見,也許和MD檔案易學、易寫、易讀、又可以很方便地寫入metadata有關。關於Markdown檔案的介紹、以及可用於編輯MD檔案的軟體,可以參閱 Markdown Guide 網站,中文化的說明可以參閱 Markdown 文件網站。
RST:以 reStructuredText 製作的文字檔,主要用於 Python 程式語言社群的技術文件;GPT4All特別列出RST檔案格式,可能是因為目前LLM、GenAI系統都是以Python程式語言開發。大多數人可能對RST檔案較不熟悉,若想進一步瞭解,可以參閱 reStructuredText 網站。
嵌入(Embedding)
使用Nomic嵌入API (Use Nomic Embed API):GPT4All是 Nomic Inc. 開發的產品,除了GPT4All之外,這家公司的主要產品之一就是 Nomic Embedding。這項設定是讓使用者透過 API 使用 Nomic 所提供的 embedding model,但使用者必須從 Nomic 網站取得 API Key。
embedding 是 LLM、RAG 建置或調整過程中的重要項目,不同的 embedding model ,會影響後續 GenAI 的生成內容;尤其對英語以外的語言來說,embedding model 是開發或調整LLM時的重要考慮因素。著名的Hugging Face平台有一個 Embedding Leaderboard (Embedding 排行榜),列出眾多 embedding model 的排名及各項指標的積分,有興趣研究的使用者可以參考。
Nomic API 金鑰 (Nomic API Key):若使用者透過 API 使用 Nomic 所提供的embedding model,必須在這個欄位輸入 Nomic API Key。
嵌入裝置(Embeddings Device):使用者可以在這個欄位指定要用來執行embedding model的裝置,選項包括「應用程式預設值」(由GPT4All依照本機電腦規格自動選定)、「Metal」(僅適用於Mac電腦)、「CPU」、「GPU」(若本機電腦無GPU則不顯示)。
顯示(Display)
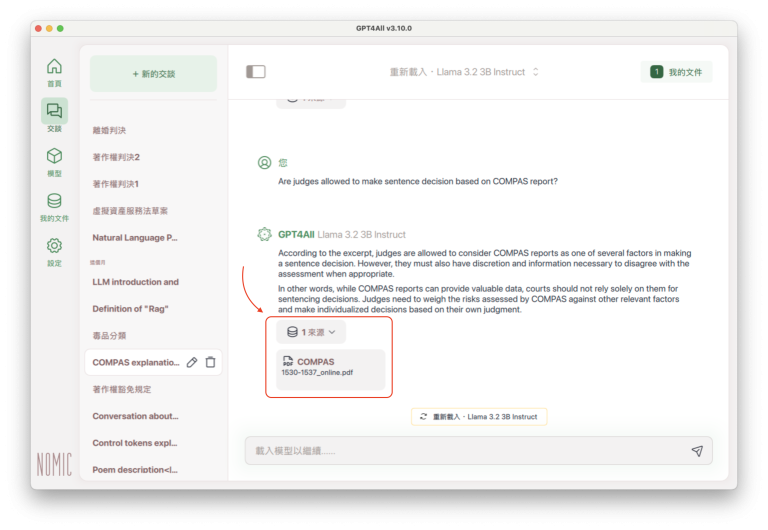
查看來源(Show Sources):如果勾選這個選項,而且在開始交談前已經匯入指定使用的資料或文件,在LLM回覆內容的下方,會標示回覆內容所根據的文件檔案名稱,方便使用者驗證LLM回覆內容的正確性:
進階(Advanced)
以下二個設定值,GPT4All都已經有預設的設定值。依照GPT4All的警語,這二個設定值如果調高,可能有助於LLM回覆的正確性,但也可能導致生成速率緩慢、甚至無法執行:
文件片段大小(Document snippet size (characters)):這應該是指chunking (將匯入文件切分為較小的片段)時,每個片段的大小。較大的分切片段,可能有助於前後文義的掌握,但執行速度可能會受較大影響。
每個提示詞的最大文件片段(Max document snippets per prompt):這是指GPT4All從之前使用者所匯入的文件中擷取內容、以供輸入LLM生成回覆內容時,所能擷取的最大文件片段數。之前所匯入的資料和文件,會由GPT4All使用embedding model分切為片段之後建立向量資料庫(vector database),使用者開啟交談、輸入提示後,會從向量資料庫中擷取相應的文本片段,再送入LLM生成回覆內容。如果從資料庫中所擷取的文件片段較多,可能可以提升LLM生成回覆內容的正確性,但由於計算複雜度提升,執行速度可能大受影響。
Restroe Defaults:使用者調整過各項設定值之後,如果有必要,可以點選「恢復預設值」,將所有設定恢復為預設值。
結語
在ChatGPT出現之後,生成式AI大受歡迎,帶動生成式AI及相關應用的蓬勃發展,而且發展速度越來越快。AI已經不再是科幻電影裡的想像,也不再是隱藏在手機等科技產品或網站背後的隱形推手,可以預見,不只是產業發展,AI會像20年前的網際網路一樣,遍佈而且深入日常生活的每一個層面,工作內容和工作方式也會非常不同。
也許,從使用者的角度來看,熟悉ChatGPT等AI工具的使用就已足夠,但如果要理解AI科技發展的內在化影響、培養隨著科技發展而延伸或增強的核心能力、甚至參與AI及周邊產業的發展,更進一步了解AI科技的ABC,不但可以提升對AI工具的掌握能力,也有助於在過程中衍生更多的可能性,而且,非常有趣。
GPT4All可能不是最強、最合用的AI應用工具,也有相當多的限制,但很可能是目前解構生成式AI運作方式的最簡單工具,希望這些簡單的介紹,可以對有興趣的使用者有幫助。